En mi caso trabajo con textos de párrafos bastante largos y con pocos puntos, por lo que los segmentos suelen ser bastante largos y eso penaliza a la hora de obtener una memoria de traducción más útil.
Sé que hay herramientas que permiten definir cómo segmentar un texto (después de coma, después de punto y coma, excepciones de segmentación, etc.) pero en Trados no veo cómo se hace.
¿Es posible hacerlo con Trados? En caso contrario ¿Qué herramientas recomendáis? ¿Cuáles creéis que son las reglas más adecuadas para aprovechar la memoria de traducción generada y a la vez no convertirla en prácticamente un glosario?
Se agradece cualquier aporte adicional relacionado con este tema.
Hola, Zótico.
Sí, es posible cambiar las reglas de segmentación. Están asociadas a la memoria de traducción, que es lo que hace que se segmente el documento. Por tanto, debes configurarlas en la memoria, ya sea al crearla, o bien, luego cuando ya la tienes.
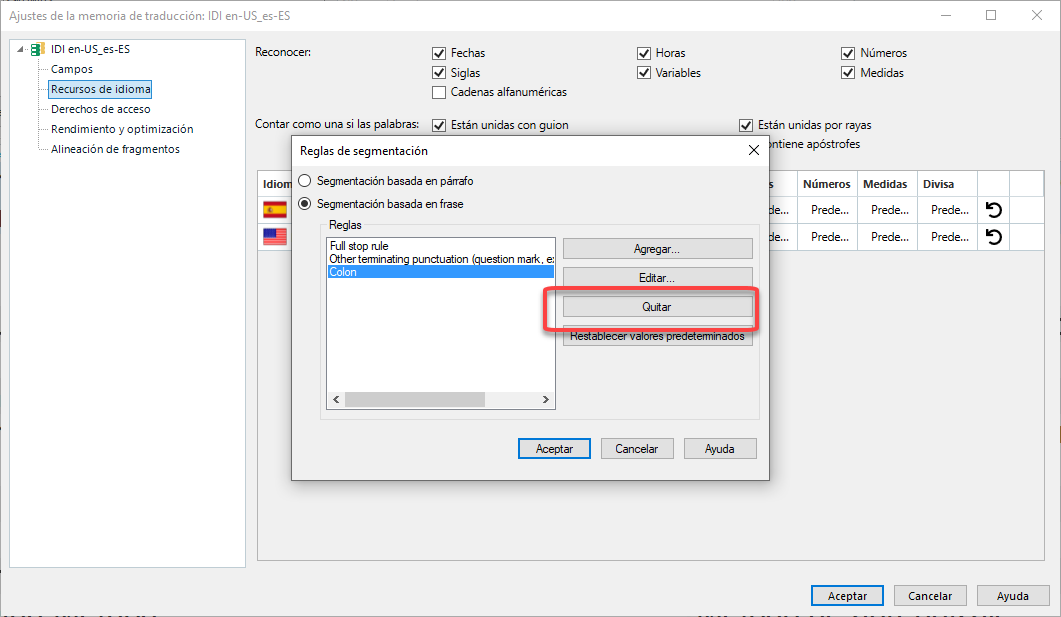
Para hacerlo, abre la memoria de traducción en la vista Memorias de traducción y allí haz clic derecho sobre la memoria > Configuración > Recursos de idiomas > Reglas de segmentación. Allí te permitirá editar las reglas que vienen predeterminadas.
Ten presente, además, que existe la posibilidad más fácil de dividir los segmentos largos. Esto yo lo aplico mucho en textos jurídicos. Siempre que se pueda, divido el segmento en 3, 4, 5, etc. partes para facilitar la traducción y la posibilidad de contar con coincidencias parciales en el futuro.
Para más ayuda, si quieres puedes compartir algunos ejemplos de oraciones para ayudarte a elegir la mejor metodología.
Saludos.
Damián
Buenos días Damián, muchas gracias por tu respuesta.
Sí, he estado investigando el tema y lo empiezo a entender.
Mi caso particular es el siguiente:
Yo suelo trabajar en el mismo campo y con textos que tienen la misma estructura. Además tengo un corpus muy extenso que me gustaría trasladar a una memoria de traducción para aprovechar todas las posibilidades de Trados así que para ello debo alinear muchos documentos para generarla. Mi cliente está empezando a incorporar Trados y me proporciona su memoria con su segmentación, pero ésta no coincide con la que el programa te pone por defecto con lo que el trabajo de alineamiento resulta inútil.
Lo que quiero hacer es extraer los ajustes de segmentación de la TM del cliente y aplicarlos a mi TM de modo que mi alineamiento sea útil cuando el cliente me proporcione su memoria. Se me ha ocurrido hacer mi alineamiento con la memoria del cliente para intentar forzar al programa a que adopte esas reglas, pero parece que no funciona.
¿Hay alguna forma de extraer las reglas de segmentación a partir de una memoria de traducción? Entiendo que después solo habría que crear una Nueva plantilla de recursos de idioma y aplicarla a todas las TM en las que queramos implementar dichas reglas de segmentación.
Hola, Tico.
Sí, en principio podrías usar los mismos pasos que te comenté más arriba para ver si la memoria de traducción del cliente tiene reglas de segmentación muy distintas, o bien, cuáles son esas reglas de segmentación para que vos puedas aplicarlas.
De todos modos, me gustaría, si es posible, que me pongas algunas capturas de pantalla de ejemplos de segmentos que estén en la memoria del cliente y de cómo te abre a ti Trados los segmentos nuevos a traducir, para tratar de entender claramente el problema.
En cuanto al corpus que quieres incorporar a la memoria, ¿no es el ya proporcionado por el cliente? En todo caso, me gustaría ver también una captura de pantalla de un archivo original y uno traducido que enviarías a una memoria de traducción, y a su vez, un archivo nuevo para traducir.
Si quieres, podemos seguir este tema por correo privado para que no pongas la información en el foro del grupo. Mi correo es damian@decodels.com.
Saludos.
Damián
También estoy intentando entender cómo funciona la segmentación.
Lo que no entiendo es cómo cambiar la segmentación del texto fuente. La memoria está segmentada perfectamente, pero el texto fuente no está segmentado como yo querría (concretamente, se segmenta en los dos puntos (":") y yo quiero que lo haga solo en los puntos (".")).
Aparte, conceptualmente no entiendo qué tiene que ver la memoria en todo esto, puesto que podría querer traducir el documento son cargar ninguna memoria.
¿Cómo hago, entonces, para decirle dónde segmentar el texto fuente?
Hola, Valentina.
Trados usa la configuración de la memoria para abrir el documento (es decir, segmentarlo). Esta configuración por defecto se puede cambiar para que, por ejemplo, no te segmente por los dos puntos. Si bien es cierto que podés abrir el documento sin memoria, no es el uso estándar del programa.
Para cambiar el método de segmentación de la memoria, tenés que abrirla en la vista Memorias de traducción, hacés clic con el botón derecho del mouse sobre la memoria y seleccionás “Configuración”. Allí vas a ir a Recursos de idioma donde encontrás la opción Reglas de segmentación. Tenés que elegir las reglas del idioma de destino de la memoria y seleccionar “Haga clic para editar”. Allí, podés eliminar “Colon” de las opciones para que no segmente por dos puntos: